
"Find all students from NY with 3.0 grade point, majoring in English, whose parents are alumni, and who have less than $5000 in student loans."
Once upon a time there was an HP 3000 site that had many user reports like the one above. Although their database was small, it was complex, with many links from the student master to the detail datasets about the student. Some reports like the one described above took two hours or more to run and interfered with interactive response.
Why were these reports taking so long and what could we do to help?
These were straightforward COBOL programs, such as you or I might write. They went serially through the student master, and for each student, they did a keyed DBFIND/DBGET on the each of the related details, looking for the information on that student (i.e., "state" is in the Address dataset, etc.).
Then I had a brain wave!
There must be a faster way to do this. Using Suprtool I knew that I could scan his or her entire database in just a few minutes, looking at every single bit of information about every single student!
Maybe using the indexed DBFINDs was not always the fastest way to retrieve complex related data.
Figure 1.
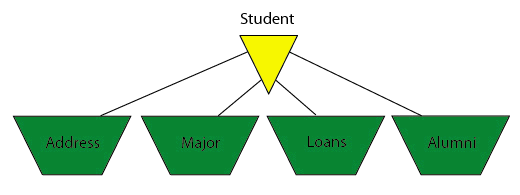
Quickly I put together a Suprtool job that serially scanned each of the five datasets, extracting and sorting the relevant data by "studentid". Here are the commands I used, creating 5 files, all sorted by "studentid".
>get student; if gpa>=3.0; extract studentid,name; sort studentid >out tmpstdnt,link,temp;xeq >table gpa30,studentid,sorted,tmpstdnt,hold >get address; if state="CA" and $lookup(gpa30,studentid) >extract studentid,state; sort studentid >out tmpstate,link,temp;xeq >get major; if degreegoal="ENGLISH" and $lookup(gpa30,studentid) >extract studentid,degreegoal;sort studentid >out tmpmajor,link,temp;xeq >get loans; if totalamt<500000 and $lookup(gpa30,studentid) >extract studentid,totalamt;sort studentid >out tmploans,link,temp;xeq >get alumni; if relationship="PARENT" and $lookup(gpa30,studentid) >out tmpalumn,link,temp;xeq
Then I spec'ed out a COBOL program to read the five files simultaneously, mashing together the records with a matching "studentid", dropping those students who did not have an entry in all five files. The result was a report containing only the students who matched all the criteria.
And the execution time for the entire job was 20 minutes!
How Was Such an Improvement Possible?
How could the "indexed" approach be so slow and the brute-force "serial-sort" approach be so much faster?
Here is the explanation that I came up with. Visualize a hard disk containing the 5 datasets of this database, spread out across the disk space.
Figure 2.
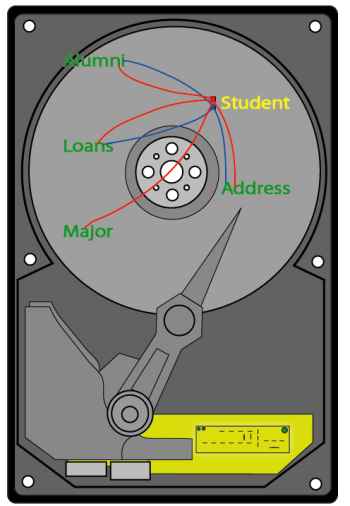
When you do indexed DBFINDs and DBGETs by "studentid", you are causing the read head on the disk to jump all over the drive, physically moving the mechanism for each call. This means that you are using the disk drive in the slowest way possible: random access.
When you do serial scans of a dataset, each entry retrieved is adjacent to the preceding entry, thus reducing the number of disk accesses needed, sometimes dramatically. For each new entry that you retrieve, you also retrieve the adjacent entries in the same disk page.
And with Suprtool, the contrast is even more vivid, since Suprtool reads about 50,000 bytes of adjacent entries with each disk access. Assume that each entry occupies 250 bytes, then each disk read would retrieve 200 entries! Suprtool is using the disk hardware in the fastest way possible.
In addition, Suprtool saves the CPU overhead of the database calls, replacing them by a few file system calls and some highly optimized sort operations.
Suprlink Is Born
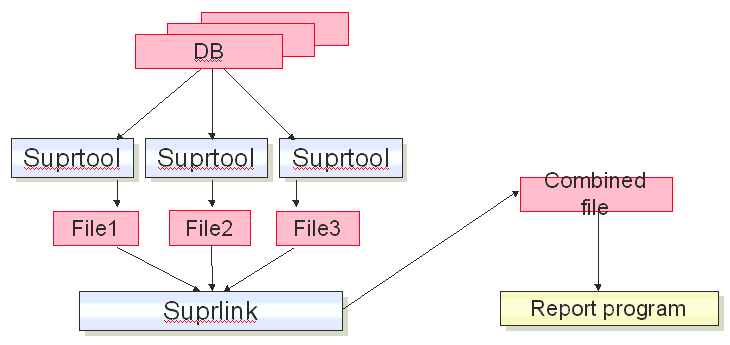
This experiment in using serial scans and a custom link program generated major performance improvements, reducing run times by up to 6 times and chopping cpu times as well. This so impressed me that I immediately sat down and wrote Suprlink, a highly efficient program for linking together the files created by Suprtool.You print the report from the Suprlink combined output file and you discard the five input files.
Figure 3.
For years, people had been telling us "We love Suprtool's speed, but couldn't we have multiple dataset extracts too?"
What they were really asking for was fast multi-dataset extracts, because they were accustomed to Suprtool's high speed. We resisted adding regular indexed lookups to Suprtool because we knew the result would often be slow performance.
With Suprlink, we could give them multi-dataset extracts and a big performance improvement at the same time. We made Suprlink an integral part of our Suprtool product, and every site that has Suprtool also has Suprlink.
To link the five files created in the example above, you add these commands to your Suprtool task:
>link input tmpstdnt >link link tmpstatework >link link tmpmajor >link link tmploans >link link tmpalumn >link output tmpfinal,temp,link >link xeq
When Suprlink is combined with Suprtool's serial extract and sort, you can do:
- multi-file linking with remarkable speed
- link anything that Suprtool can read as a data source: IMAGE, KSAM, MPE files, Oracle tables, Eloquence, ...
- merge up to 8 files into one
- and create one sorted file as input to your report program
Suprlink combines data from multiple datasets, files or other sources, into a single file. The combined output file contains data fields from all the input files.
In our example above, we combined data from five IMAGE datasets, but the files can come from anywhere.
They do not have to be IMAGE datasets. They do not even have to be HP 3000 data. With Suprlink you can link a dataset to flat files or indexed sequential files. Suprlink works with the same efficiency, no matter where the data comes from, or how the original data is indexed (or not!).
Suprlink uses common data values in the related files to link the records. In our example above, it was the "studentid", which occurred in every file and had the same field name. Having the same name is optional, as long as the fields have the same values.
You can link on any common field. You can even link on non-index fields. This avoids the need to add expensive index paths into the database, just to retrieve occasionally for reports.
Self Describing Files (SD)
The files you feed to Suprlink are "Self-Describing files", created by Suprtool. The SD format is openly published and based on the original SD files of Query/3000. In our student report, Suprtool scanned the Student, Address, Major, Loans and Alumni datasets, generating temporary SD files that contained the qualifing entries.A self-describing file (SD) contains both the data and the description of the data. In our example, we did not have to tell Suprlink the names, sizes and positions of the fields in each temporary file - it knew that because they are self-describing. We did not have to tell Suprlink that they were sorted by "studentid" - it also knew that because they are self-describing.
If you generate an SD file with Suprtool on MPE and transfer it to HP-UX, you can then input it into Suprtool/UX and immediately be able to use the field names. Suprtool/UX can even know which fields are dates (and in what format) and how many decimal places the numeric fields contain.
SD files are moved from MPE to HP-UX using our SDUNIX utiilty which converts the field descriptions from the user labels (not supported on UNIX) to a separate file with a .sd extension. Then you just FTP the two files to HP-UX.
SD files are the key method of preparing data for Suprlink and STExport.
And since we have ported SD files to HP-UX, you can generate them with Suprtool/UX, and use them in Suprlink/UX and STExport/UX as well, not just with the MPE versions of the products.
For more information on SD files, read this paper.
Suprlink Pros and Cons
|
Advantages
Faster results when you need to look at more than a few entries. Does not require the overhead drag of database indeces. You can link to data source that Suprtool reads (flat files, files copied from other systems, databases, indexed sequential files, etc.). Portable between MPE and HP-UX. |
Disadvantages
Uses a great deal of temporary disk space, but gives it all back at the end. Works on a single common field, must resort data to link by another field. Only one input source can have multiple entries with the same link value (i.e., no "many-to-many" links). Update: in version 4.6.03, with the addition of the Join command, this restriction was lifted from Suprlink. Requires a bit more coding than a "link to" in Quiz. |
A Table Can Also Replace An Index
A Suprtool Table is a list of extracted data values, sorted by a single field and accessed by a binary search. In our example above, we created a table of students with 3.0 GPA, and then did lookups on it while scanning the other four datasets, ensuring that the entries we select are only for students with a 3.0 GPA.The in-memory binary search of the qualified students is generally much faster than the standard DBFIND/DBGET calls that would normally be made.
For more on Tables, read this article on replacing Quiz links with Tables.
Update From a Table (MPE Only)
Another feature of Suprtool Tables that can be used to eliminate explicit database links is to extract related fields from the table and insert them in the output record.
In our example above, the Table "gpa30" contains just the "studentid". We only used it to see if the student was on the list of those with a 3.0 GPA, but we could have used the same table to append the student "name" to one of the other SD files.
Here is the first part of our student example, recoded so that our "gpa30" table contains both the id and the name. When we select the student address, we will append the student name to it. The name is extracted from the table of students with 3.0 GPA. This eliminates the need to input the "tmpstdnt" file into the Suprlink phase.
>get student; if gpa>=3.0; extract studentid,name; sort studentid >out tmpstdnt,link,temp;xeq >table gpa30,studentid,sorted,tmpstdnt,data(name),hold >get address; if state="CA" and $lookup(gpa30,studentid) >extract studentid,state >define extractname,30,byte >extract extractname=$lookup(gpa30,studentid,name) >sort studentid >out tmpstate,link,temp;xeq
Linking by Multiple Keys
Update from a Table is also extremely handy when you need to link by more than one key field.
Remember that Suprlink can only link files with a common field. What if we need to add the student advisor's name and telephone number to the data? This is probably in an Advisor dataset indexed by an advisor number.
Without tables, we would need to add the "advisornum" to our our Suprlink output file from the example and then resort it by that field at the end and run Suprlink again to link in the sorted advisor records.
Instead of resorting we could just put the advisor numbers, names and telephone numbers into a second table and extract the relevant advisor name while we are scanning the Student master dataset.
As you can see, tables are very useful when you have more than one key! They extend the range of applications where you can use Suprtool and Suprlink to extract the data that you need.
Conclusion: Software for Homesteading
The HP 3000 has many third-party tools that will extend the life and power of the system. These tools often lie installed, but unnoticed and unused.Suppose you need to extract information on a group of students, expanded with related fields from the address, loans, alumni, and majors tables. The standard technique that most report writers use is to randomly retrieve all the data for a single student from all tables, decide whether to retain that student in the report or not, then go back to the tables and look up the next student. If you examine a large number of students, this method can be quite time consuming, because it uses the disk hardware in the least efficient way possible. In fact, it can take much longer than scanning the entire database serially from start to finish.
One of those under-used third-party tools can be help here. Suprlink, a part of the Suprtool product, is designed to speedily link related data.
Suprlink is a unique program - it allows you to tradeoff temporary disk space (which is cheap) for clock time, which is always in short supply.
With Suprlink, you use Suprtool to serially scan the tables for your selected students, creating a sorted Self-Describing file from each table. Then Suprlink reads all the extract files simultaneously and merges the related fields together into a new, wider record with all the fields. It is amazingly fast.
Many of you already have Suprlink on your system, since you are already Suprtool users. But you may never have used it. Quite often, revising two of your slowest reports to use Suprlink can make it seem like you have upgraded the server - especially if the reports must run during the workday.
Taking better advantage of the tools available to you can extend the life of your HP 3000 system.
P.S. Suprlink makes just as much sense on HP-UX as it does on MPE. So when you do eventually migrate one of your applications, you do not have to change the logic and coding of the extracts.
P.P.S. We continue to vigorously enhance Suprlink. In February 2003 we added a many-to-many Join command!