
TurboIMAGE - Tips, Explanations and Techniques
New Interest in IMAGE Logging - Part II
By Bob Green, Robelle
Last month we talked about the basics of enabling and using transaction logging with TurboIMAGE. That discussion was mainly in the context of providing an audit trail for database changes. This month we examine logging from data protection point of view, examining the issue of "broken chains" and logical data consistency.Broken Chains
Under the original IMAGE database, broken chains were a frequent topic of discussion. Now that we have the Transaction Manager on MPE/iX, broken chains are a minor issue. Let's see why. A broken chain typically occurs when you do a chained DBGET and the next entry (e.g. record) on the chain cannot be found. So what is a chain? It is a list of entries that have the same key value (for example, all Line-Item entries with Order-Number 123005). Each IMAGE entry in Line-Item maintains a forward and backward chain pointer. If those pointers become corrupted, they way you will notice is when your application program reports a broken chain.Before Transaction Manager (XM), a broken chain could happen when the system crashed while in the midst of a DBPUT or DBDELETE operation. One of the entries had been updated on the chain, but the other entries that point to it had not all been updated. With Transaction Manager, the operating system keeps track of all writes to the disk drives for TurboIMAGE. When recovering from a system failure, XM ensures that all the writes for a single DBPUT call are either completed, or are rolled back. In either case, the database is left in a physically consistent state.
Below are some email exchanges that help clarify "broken chains". They are from a Jon Diercks' 2001 Threads column on the Interex web site.
www.interex.org/pubcontent/enterprise/nov01/thrd1101.jsp
From: Gibson Nichols (gib@juno.com)
From: Larry Simonsen (LSimonsen@flowserve.com)
From: Gibson Nichols (gib@juno.com)
From: Dennis Heidner (dennis@heidners-no-spam.net)
Each process running has a special hook put into it so that when it terminates and the process has a IMAGE database open, the abort process handler is called. It ensures that the database is closed in an orderly manner.
Broken chains could be a symptom of a TurboIMAGE bug, defective hardware, using deferred posting, and system aborts.
Phantom broken chains can be reported if you are using a weak locking scheme, i.e., changing key value or deleting entries while another process is walking the same chain.
A programmer asked me if doing an ABORTJOB on a program will cause a broken chain in an IMAGE database.
Yes, from a logical frame the database may have only 1/2 of a transaction. But, from a relationship view there should be no broken chains.
I've seen six broken chains (different systems, all on 6.0) in the past twelve months.
But that doesn't mean ABORTJOB is causing the problem.
The last point by Dennis Heidner is important. If you don't lock while reading the entries on a chain, then another user could be changing the chain and you could get a broken chain error. But these are only phantom broken chains. If you rerun the code, you will not get the error again. It is possible that such phantom broken chain errors have been eliminated in the most recent versions of TurboIMAGE.
Logical Consistency
In the email exchange above, Larry Simonsen says "from a logical frame, the database may have only � of a transaction." Let's look into that.A typical logical transaction would be the creation of a new order. This might involve a DBPUT to Order-Header and several DBPUTs to Order-Line. The Transaction Manager ensures that you will get a complete Order-Line entry that is properly linked to the other lines for that order and customer, but it does nothing to ensure that you get the entire order.
XM does not guarantee logical consistency of your data.
How do you ensure logical consistency?
You use DBXBEGIN and DBXEND calls around all the DBPUT, DBUPDATE and DBDELETE calls that you make for your logical transaction.
Yes, the definition of a logical transaction is up to the programmer.
There can be a lot of confusion about logical consistency, mostly because IMAGE kept adding logging and recovery features over a 30-year period. Luckily, Gavin Scott gives a clear explanation of the current state of affairs in the same email exchange linked above:
From: Gavin Scott (gavin@allegro.com)
"Real" broken chains are (supposed to be) impossible to achieve with IMAGE on MPE/iX, no matter what application programs do, or how they are aborted, or how many times the system crashes!
The Transaction Manager (XM) provides absolute protection against internal database inconsistencies, as long as there are no bugs in the system and as long as the hardware is not corrupting data. No action or configuration is required on the part of the user.
Logical inconsistencies (order detail without an associated order header record, for example) can easily be created by aborting an application that's in the middle of performing a database update that spans multiple records. Of course, IMAGE doesn't care whether your data is logically correct or not, that's the job of application programmers.
Using DBBEGIN/DBEND will have no effect whatsoever on logical integrity, unless you actually run DBRECOV to roll forward or roll back the database to a consistent point every time you abort a program or suffer any other failure.
By using the DBXBEGIN/DBXEND "XM style" transactions, you can extend IMAGE's guarantee of physical integrity to the logical integrity of your database. The system will ensure that no matter what happens, either all changes inside a DBX transaction will be applied, or none of them will be. Of course, it's still possible to use this feature incorrectly (locking strategies are non-trivial as you need to lock the data that you read as well as that which you intend to write in many cases).
MPE/V introduced a feature called Intrinsic-Level Recovery (ILR) which could be (and still can be) enabled for a database. This was sort of a mini-XM that forced updates to disk each time an Intrinsic call completed in order to ensure structural integrity of the database in the face of system failures.
I believe that on MPE/iX, enabling ILR for a database does something really nasty like forcing an XM post after every update intrinsic call, which is a serious performance problem. ILR is no longer required on MPE/iX as XM will ensure integrity without it. With ILR you might be guaranteed that every committed transaction will survive a system abort, whereas without it XM might end up having to roll back the last fraction of a second's worth of transactions. For almost any application this difference is negligible. Do not turn ILR on!
There are more complexities if your application performs transactions that affect multiple databases or databases and non-database files. It's possible to do multi-database IMAGE transactions, but only if the databases reside on the same volume set, I believe.
It's amazing how much superstition exists surrounding this kind of stuff, and how many unnecessary rituals and sacrifices are performed daily to appease the mythical pantheon of data integrity gods.
There are still a number of other logging issues that are worth exploring, but we will leave them until next month.
New Interest In IMAGE Logging
The system is down - the hard drive is toast - you may have to restore your IMAGE database from yesterday's backup. In the past, this is the scenario that typically got HP 3000 system managers interested in the transaction-logging feature of the TurboIMAGE database.But now, as a result of the Sarbanes-Oxley law (SOX), IMAGE Logging is also being used to create audits for data changes. Managers who have never used transaction logging before are now enabling it to create an evidence trail for their SOX auditors.
Here is an example from 3000-L at http://tinyurl.com/cok6z
Date: Mon, 28 Jun 2004 14:02:23 -0400 From: Judy Zilka <judy_zilka@ANDERSONSINC.COM> Subject: Sarbanes Oxley - Data change logAs a requirement of Sarbanes-Oxley we are in need of a HP3000 MPE system program that will automatically log changes to Image data sets, ksam and mpe files with a user id and time/date stamp.
We often user QUERY to change values when a processing error occurs and the user is unable to correct the problem on their own. The external auditors want a log file to be able to print who is changing what and when.
George Willis and Art Barhs suggested IMAGE Transaction Logging:
Judy, we have enabled Transaction Logging for our TurboImage databases
coupled with a reporting tool known as DBAUDIT offered by Bradmark. For
your other files, consider enabling a System Level logging #105 and
#160. The LISTLOG utility that comes with the system can extract these
records and provide you with detail or summary level reporting.
- George
Hi George & Judy :)
Yep, Transaction Logging will meet the requirements for Sarbanes-Oxley
and HIPAA for requirements relating to tracking "touching" data.
Also, remember you *MUST* have a corporate policy relating to this tracking and either a SOP and/or a formal procedure for reviewing the logs. The SOP and/or procedure needs to address what constitutes normal and abnormal activity with regards to reviewing the logs and what action to take when abnormal activity is noted.
- Art "Putting on the InfoSec Hat " Bahrs
P.S. the fines for not being able to show who did what and who has access to what can be very, very eye opening!
P.P.S. um... of course these comments only apply to the U.S. and businesses linked into the U.S.
So what is IMAGE logging?
First of all, it is not the same as "system logging" or system "logfiles". These record MPE system activities such as logon and file open, and have their own set of commands to control them. You can see in George's answer above that he suggests system logging to track KSAM and file changes.IMAGE logging is a variety of "user logging" and is a part of the TurboIMAGE database application. Once enabled, it writes a log record for each change to a database. There are two programs that can be used to report on those database log records:
1) LOGLIST (a contributed program written by Dennis Heidner; I am not certain what the current status of this program is).
2) DBAUDIT (a product of Bradmark; in the spirit of SOX disclosure, I must admit that I wrote this program and it was a Robelle product before we sold it to Bradmark!)
3) One day after I finished this article, I received an Online Extra newseltter from Ron Seybold at the Newswire. In it was an advert for a new IMAGE logging report program, 3000Audit as an aid in SOX audits!
Setting Up IMAGE Logging
A number of MPE Commands are used to manage IMAGE logging; see the MPE manual at http://docs.hp.com/en/32650-90877/index.html:altacct green; cap=lg,am,al,gl,nd,sf,ia,ba :comment altacct/altuser add the needed LG capability :altuser mgr.green; cap=lg,am,al,gl,nd,sf,ia,ba :build testlog; disc=999999; code=log :getlog SOX; log=testlog,disc ;password=bob :comment Getlog creates a new logid :run dbutil.pub.sys >>set dbname logid=SOX >>enable dbname for logging >>exit :log SOX, start :log SOX, stopYou can use the same Logid for several databases. For a more detailed description, see Chapter 7 of the TurboIMAGE manual, under the topic "Logging Preparation". The web link is http://docs.hp.com/en/30391-90012/30391-90012.pdf
IMAGE Logging Gotchas
Although the basics of user logging are pretty straightforward, there are still plenty of small gotchas. For example, Tracy Johnson asks about backup on 3000-L atIf when backing up Image Databases that have logging turned on and you're not using PARTIALDB, should not the log file get stored also if you store the root file? This question also applies to 3rd party products that have a DBSTORE option.
Tracy continued:
One problem I've been having is that since a log file's modify date doesn't change until it is stopped, restarted, or switched over, one might as well abort any current users anyway, so any log files will get picked up on a @.@ "Partial" backup, because DBSTORE and "online" (working together) features won't do the trick. Because even though a root file's modify date gets picked up on a Partial backup, the associated log file's isn't.
Then Bruce Hobbs pointed out that there is the Changelog command to close the current logfile before backup (which ensures that its mod-date is current and that it will be included on the backup) and start a new logfile.
Later Tracy runs into another interesting gotcha regarding logging and the CSLT tape (see http://tinyurl.com/c37vr):
IF YOU USE IMAGE LOGGING, ALWAYS MAKE YOUR CSLT THE SAME DAY YOU NEED TO USE IT!
(Or make sure no CHANGELOG occurred since the CSLT was made.)
(Thanks be to SOX...which forced Image logging.)
We added so many log files identifiers for each of our production databases it reached the ULog limit in sysgen of 64 logging identifiers. So, per recommendations of this listserv (and elsewhere,) I had to update the tables in sysgen and do a CONFIG UPDATE this weekend to bring it to the maximum HP ULog limit of 128.
Not a problem. Stop the logging identifiers with "LOG logid,STOP"
Shut down the system and BOOT ALT from tape. System came up just fine!
UNTIL it was time to restart logging! Every logging identifier reappeared with old log file numbers a few days old. (We do a CHANGELOG every night and move the old log file to a different group.) I scratched my head on this one for half of Sunday.
. . . details snipped . . .
- - - - - - <Epiphany Begin> - - - - - - - -Then it occurred to me, the Log file numbers the system wanted were from the day the CSLT was created. I had made it before the weekend, thinking it would save me some time before the shutdown!
- - - - - - </Epiphany End> - - - - - - - -Therefore:
a. Logging Identifiers retain the copy number on the CLST tape in the case of an UPDATE or UPDATE CONFIG.
b. Logging Identifiers on the system retain the NEXT log file they need to CHANGELOG to.
So if one needs to use a CLST to load and you're using Image Logging, remember to use it just after you create it, or make sure no CHANGELOGs occurred since it was made.
This may effect some sites as they may believe their CPU is a static configuration and only do a CSLT once a month or once a week. In the case of an emergency tape load, to save some heartache rebuilding image log files, they may need to do a CSLT every day.
The Three Bears of IMAGE
In a classic paper title "The Three Bears of IMAGE", Fred White of Adager explains three features that can be disastrous if mis-used: Integer Keys, Sorted Paths, and too many paths.http://www.adager.com/TechnicalPapersHTML/ThreeBears.html
Here is how Fred begins his discussion of Sorted Paths:
Mama Bear: the SORTED PATH pitfallMy first live encounter with a misuse of sorted paths arose in 1975.
The facts surrounding this incident were told to me by Jonathan Bale who was still on the IMAGE project. Neither one of us remembers the exact numeric details so I have used poetic license by making up numbers which seem to be reasonably close to the actual ones involved in the incident.
The user had created a database containing one automatic master dataset and one detail dataset related by a 2-character key and where the resulting path was sorted by some long-forgotten field(s).
The user had written a program which read a record from an input file, added two blank characters to serve as the search field and then performed a DBPUT to the detail dataset. This was repeated for all records of the input file.
At the time that Jon received a phone call, the tape had not moved for around 10 hours and the program had already been running(?) for at least 30 hours. . . . [Read the entire paper.]
Paths are for People
By Bob Green, RobelleImagine you have a customer order tracking system and you need a weekly report on sales by salesman. Many programmers automatically think of making the salesman code into a TurboIMAGE search key in order to optimize the report. Is this a good idea?
First a little background information, which may be review for many readers.
A path is the structural relationship between a TurboIMAGE master dataset and a TurboIMAGE detail dataset linked through a common search item.
For example, the customer master dataset provides the index for unique customer names as well as the customer name and address. The line item detail dataset provides information on what a customer has ordered: customer number, item number, quantity, price, order number, salesman code, date ordered, date shipped, etc. There can of course be multiple line items per customer, and usually over time there are many. A path between the two datasets allows you to retrieve the line items for a specific known customer number.
A chain is a collection of detail entries that have the same search value; the head of the chain is in the master entry for that search value. The head of the chain points to the first detail entry with the search value, and the last one. Each detail entry has a forward and backward pointer, so retrieving the list of entries is relatively easy and fast (a maximum of one disk read per record). This is implemented in TurboIMAGE as a DBFIND followed by chained DBGETs (mode 5).
Every path you add to a TurboIMAGE dataset adds overhead and slows response time, because the pointer chains must be changed for each DBPUT and DBDELETE into the detail dataset. The more paths, the more chains to update. And this overhead usually occurs at the worst possible time: when the end-user is entering or amending an order.
To decide how many inquiry paths you should have for a dataset, you need to know the volatility of the dataset: how often do people ask questions about the data (read access) versus how often they update the search keys in the data (write access)? The read/write ratio tells you whether the dataset is stable or volatile.
If the read/write ratio is low, you should not have many search paths, because the overhead of updating them during the many writes will overwhelm the benefit during the few reads. For example, a dataset that contains active customer orders is probably active.
However, if the read-write ratio is high then the dataset is more stable (i.e., it doesn't change that quickly). You can afford many more search keys in such a dataset. For example, a dataset that archives completed customer orders is probably very seldom (if ever) updated. Spending a second or more to write a record into this dataset makes sense, because it gives you many search keys per record and is only done once.
Suppose you only write records 500 times a day: the total CPU time will be less than 10 minutes each day. And even if the system is called upon to search for over a million records a day, the heavy use of keys will make the overall application work better. The only way to be confident that you have properly indexed your data is to measure, measure, measure.
The purpose of a path is to divide a dataset into small, manageable subsets of entries that can be retrieved, displayed, and updated easily for real people who are sitting at workstations!
A path should divide a dataset into many short chains, rather than a few long chains.
So a report that is only run weekly may be marginally faster with a custom search key, but the extra search keys make the on-line usage slower during the entire week
Paths are never absolutely necessary. You can accomplish the same inquiry by a serial scan of the entire dataset. The only reason for a path is to make the retrieval faster than a serial scan.
So our weekly report may actually be slower with the search key, since it may need to read all or most of the dataset anyway, in which case a serial scan is almost always the fastest approach.
If the number of unique search values is less than the number of entries per disc page, a serial scan will be faster than a chained retrieval. That is because a chained read takes one disc read, while a serial read takes only 1/N disc reads (where N is the blocking factor per page).
It seldom makes sense to add an inquiry path strictly for a batch program. Paths should be reserved for on-line users.
Serial Dataset Scans: Good and Bad
A serial scan is an access method that reads an entire dataset in physical order to find what is wanted, rather than following a search key maintained for that dataset. MPE programmers are usually taught that TurboIMAGE search keys are efficient and serial scans are to be avoided, but that is an over-simplification.There are situations where a serial scan is faster than a keyed search, and vice versa.
Good Serial Scans
Question: What are two ways to perform the following data retrieval?We have a large detail dataset called Ord-Line with 2,307,685 records. We have a list of 162,770 Ord-Num key values of interest. We want to extract the Ord-Line records for those keyvalues and we want them sorted by Ord-Num. The Ord-Line record size is 308 bytes.
Answer:
The traditional solution in TurboIMAGE is to call the DBFIND intrinsic for each of the 162,770 Ord-Num key values, then repeatedly call DBGET mode-5 (directed access) to retrieve the Ord-Line detail entries on that key-value chain (261,230 in all). If the list of Ord-Num values is sorted, the Ord-Line records will also be sorted.
An alternative solution is to call DBGET mode-2 (serial access) for each of the 2,308,685 detail entries (or use Suprtool's Get Command), select out the 261,230 records that match the Ord-Num table, then sort those records. That sounds like a lot of work, but do we know that it will be slower than the traditional search-key method?
The traditional method takes about 162,770 DBFIND disc reads and 261,230 DBGET disc reads, for a total of 424,000 disc reads. The reason why it consumes about one disc read per record accessed is that the access is random and direct - when you retrieve one record the chances that the next record retrieved is adjacent is extremely tiny.
If you do the serial scan with DBGET it takes at most 177,514 disc reads. The reason is that each disc read transfers a page containing 13 records. Suprtool uses a 50,000-byte buffer and reads 159 records of 308 bytes per disc read. If you use Suprtool to do the task, it will take only 14,500 total disc reads. The Suprtool serial scan reduces disc reads by 96.6 percent.
Suprtool can do serial scans much faster than other tools and application programs because it bypasses the overhead of TurboIMAGE by doing NOBUF/MR access to the underlying file of the dataset.
Bad Serial Scans
Question: Will a serial scan be faster than keyed access if you have 1 million entries in an TurboIMAGE master dataset and you need to retrieve 1000 key values (which you have in a table). The entries are 400 bytes long and are packed 10 records per page in the master dataset.Answer: Keyed access takes about 1000 disc reads, since master entries are stored randomly by hashing the key value. Serial access takes about 100,000 disc reads, since they are packed 10 per page. Serial access with Suprtool takes about 6,500 disc reads, since Suprtool reads 12 pages per access. So even with Suprtool, the keyed access is much faster because we are reading a small portion of the dataset.
Question: You have deleted 90,000 old entries from a dataset with a capacity of 110,000. Why does the time to serially read the dataset remain the same?
Answer: Because TurboIMAGE must scan the empty space in the dataset to find the remaining entries. There are no pointers around empty chunks in a dataset. In a master dataset the entries are distributed randomly over the entire capacity and there is no way to find the next occupied entry after N except by looking at N+1, N+2, and so on, until you find it. The time to read a master dataset is proportional to the capacity, not to the number of entries.
In a detail dataset, the entries are stored chronologically adjacent to each other. As you add entries to a detail dataset, it moves up an EOF marker called the "highwater" mark. Serial scans must read all the space up to the highwater mark. When you delete an entry, it is put on a delete-chain for reuse on the next add operation, but the highwater mark is not necessarily reduced. The time to read a detail dataset is proportional to the highwater mark, not to the number of entries.
Moral: Use a dataset packing tool such as Detpack from Adager after you clean out a detail dataset. This will reduce the highwater mark by repacking the entries. For a master dataset, reduce the capacity if you won't need the empty space in the near future.
IMAGE Internals
By Bob Green, RobelleIMAGE is the database of the HP e3000 system, and some knowledge of how it works is useful for anyone doing IT work on the system.
�Master Datasets� are one of the storage types of IMAGE and their job is to store records when there is one record expected per unique key field (also the search field). For example, one customer record per customer number.
IMAGE uses a mathematical formula called a hashing algorithm to transfer the key value into a record number within the master dataset. This �hash location� is the first place where IMAGE tries to store the record.
Figure 1 below shows a hashing algorithm with a collision - same block.
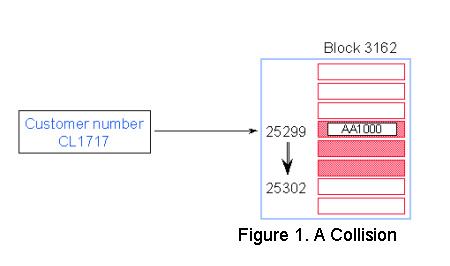
� Customer number CL1717 hashes to the same record number as AA1000 location.
� IMAGE/SQL tries to find an empty location in the same block. If it finds one, no additional IO is required.
� CL1717 becomes a secondary entry. Primary and secondary entries are linked using pointers that form a chain.
Although hashing algorithms are designed to give unique results, sometimes IMAGE calculates the same record number for two different search item values. In this case a new entry may want to occupy the same space as an existing Primary entry. This is known as a collision, and the new entry is called a Secondary.
Most master datasets have secondaries. If you have a lot of secondaries, or if they are located in different blocks, you should be concerned about generating more IOs than needed.
In Figure 1, customer number CL1717 collides with AA1000, and CL1717 becomes a secondary. IMAGE/SQL then tries to find the closest free record location. In this case, the next empty record number is 25302, which is in the same block. No additional I/O is needed.
IMAGE/SQL uses pointers to link the primary entry with its secondary. Record 25299 for AA1000 has a pointer to record number 25302 and vice versa. This is known as a synonym chain.
Several programs can help identify inefficiencies in IMAGE databases. One, a program written by Robelle and distributed to Robelle and Adager customers, is called HowMessy. There is a very similar contributed program, Dbloadng, upon which HowMessy was patterned. Another option is the report feature of DBGeneral.
All these programs produce a report that shows the database�s internal efficiency. Databases are inefficient by nature. Unless you never add new entries or delete existing entries (e.g., use your database for archival purposes), your database becomes more inefficient over time.
In the rest of this column we will examine the HowMessy/Dbloadng reports for two example master datasets.
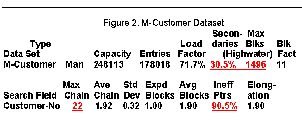
In a Manual Master Dataset (see Figure 2, above):
� The number of secondaries is not unusually high.
� However, there may be problems:
� Records are clustering (high Max Blks).
� Long synonym chain.
� High percentage of Inefficient Pointers.
The values in Figure 2 are understood as follows:
Secondaries: Percentage of entries that are secondaries
Max Blks: Maximum number of contiguous blocks IMAGE/SQL has to read before finding a free location for a secondary. This is the worst-case scenario, not the actual number.
Blk Fact: Blocking Factor column indicates the number of records in each block (not an MPE/iX page).
Search Field: Key item name.
Max Chain: Maximum number of entries in the longest synonym chain.
Ave Chain: Average number of entries in the synonym chain.
Std Dev: Standard deviation shows the deviation from the average that is required to encompass 90% of the cases. If the deviation is small, then most chains are close to the average.
Expd Blocks: Number of blocks we expect to read in the best-case scenario (usually 1.00 for master datasets) to get a whole synonym chain.
Avg Blocks: Number of blocks needed to hold the average chain.
Ineff Ptrs: Percentage of secondary entries that span a block boundary.
Elongation: Average number of blocks divided by the expected number of blocks.
Figure 2 does not show a tidy dataset. The number of secondaries is fairly high (30.5 percent, or around 54,000). The Maximum Chain length is 22. This is unusual for a master dataset. The high Max Blks value (1,496) suggests some clustering. All of this indicates that the hashing is not producing random distribution. If you add a new record whose primary address happens to be the first block of the contiguously-occupied 1,496 blocks, IMAGE/SQL will have to do many extra disk IOs just to find the first free entry for the new record (assuming that MDX has not been enabled on this dataset).
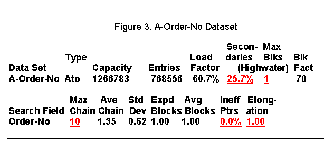
Figure 3 above shows an Automatic Master Dataset.
� This is a very tidy dataset:
� Number of secondaries is acceptable.
� Max Blks, Ineff Ptrs and Elongation are at the minimum values, even if the Maximum Chain length is a bit high
Although the percentage of secondaries is similar to that of the M-Customer dataset of Figure 2 (30.5 percent versus 25.7 percent), the longest synonym chain has 10 records with a 1.35 average. The Inefficient Pointers and Elongation are at their lowest values. Max Blks of 1 means IMAGE/SQL can find a free record location within the same block every time it searches for one.
It means the hashing algorithm is working correctly, dispersing records evenly across the dataset.
There is, of course, much more to learn about IMAGE internals and performance. This short column is to whet your appetite for a two-hour tutorial that I have presented many times: �IMAGE Internals and Performance� (pdf link).
Are adjacent detail entries likely to have the same key value?
By Bob Green, RobelleWhat is the likelihood that entries with the same key are located at adjacent locations in a detail dataset?
When we retrieve the entries for a customer from a sales detail dataset, we do a DBFIND by the customer number, then a DBGET mode 5 to read each detail entry for that customer. Our natural tendency is to think that since these detail entries are logically "grouped" they are probably physically grouped as well. If they are, then retrieving them should be very quick. However, if they are likely to be physically far apart on the disk hardware, then performance will be much less.
The entries we are retrieving have something in common - they have the same key value. They may even be in the same disk page. If so, and there are 20 entries per page (4K bytes divided by 20 equals about 200 bytes per entry), then we would use 1/20th of a disk read per entry. Sounds fast!
But what are the odds that the entries with the same key value are adjacent?
To understand when they will be adjacent and when not, we must understand how entries are stored in detail datasets.
Internally, all IMAGE datasets are organized into logical blocks of entries, with the number of entries per block being the blockfactor. The block organization is a hangover from the original design of IMAGE on the Classic HP 3000 computers (MPE V). On MPE/iX, IMAGE actually performs page-level I/O. A page has 4,096 bytes. This means that one or more IMAGE blocks are read or written as part of each I/O operation.
Whether dealing with blocks or pages, the goal is to minimize the number of I/Os required to access the database.
Starting from An Empty Detail Dataset
When a detail dataset is empty, IMAGE adds records in the order that they are created, starting from record location one.Records are stored in chronological sequence. That means records for the same customer are not necessarily stored consecutively, unless they happened to be added at the same time.
Assuming that customer id is a key, then records with the same customer id are linked together with pointers to form a chain. The first and last records in a chain are also linked from the corresponding master record for that customer id.
These chains by customer id are used when you do retrievals by customer id. IMAGE finds the matching entry in the master dataset, then follows the path chain to retrieve the detail entries..
Multiple Search Keys
Remember that only one search path per detail dataset can be optimized. If the customer id path into sales details is optimized, then the part number path CANNOT be optimized. The physical data can only be sorted one way.It is tempting to add a search path for every kind of search that your application requires, but this is a bad strategy: "paths are for people." They exist so that on-line users can retrieve and examine the entries by that path. Paths are not necessary for reports that run only once a day - you can always use Suprtool and a serial scan instead, but that is another article.
"Entropy" of Detail Datasets
As IMAGE adds more records to the dataset, the chains for any given key value get longer and span more blocks. When records are deleted, their space is added to a "delete chain" and subsequent additions are fulfilled from this list, rather than being added to the end of the dataset.Therefore, the more active the dataset is, in terms of additions and deletions, the more likely that adjacent records on a chain will be in different blocks. Over time, records for the same customer are scattered over multiple blocks
As a result, IMAGE has to perform a lot of extra disc I/O to read a whole chain for a given customer. In the worst case scenario (but a common one for active datasets), IMAGE does one disc I/O for each record in the chain.
Conclusion: it is possible for related entries to be adjacent, but only if the related entries were added at the same time and no entries have ever been deleted. For any real world dataset where entries are added and deleted dynamically over time, it is most likely that the related entries are not adjacent. A good rule of thumb is to assume an extra disk read for each entry that is retrieved.
Repacking a Detail Dataset
You can often improve performance by repacking a detail dataset. The repacking process usually groups all records along their "primary path" values. In other words, all the records for a customer are put into consecutive locations (if customer id is the primary path). Depending on the chain length, a single disk I/O may read all the appropriate records. The repacking default in Adager's Detpack and DBGeneral's dataset reorganization feature is along the primary path. For various reasons, you may not want or be able to change the primary path. If that is the case, both products give you the option to use any other path in the dataset.Repacking removes the delete chain. It groups all the records at the beginning of the dataset without leaving empty locations in the middle of blocks.
Because most tools repack a dataset along the primary path, it is essential to pick the right one. A primary path should be the one with the longest average chain length (you can get this figure from Robelle's HowMessy report), that is also accessed the most frequently.
There is nothing to gain by selecting as your primary path a path with an average chain length of 1, since there is never another record with the same key value to retrieve.
Repacking only improves statistics for the specific path that is repacked. Other paths will usually not be improved in efficiency by a repacking.
For more information on how the internal mechanisms of IMAGE impact performance, read this Robelle tutorial "IMAGE Internals and Performance" at www.robelle.com/library/tutorials/pdfs/imgperf.pdf
IMAGE: Can you increase your capacity too much?
By Bob Green, RobelleYou have probably heard that increasing the capacity of a TurboIMAGE master dataset will improve the performance. So wouldn't increasing the capacity a lot be really good for performance?
First, let's review why increasing the capacity can improve the performance of Puts, Deletes and Keyed Retrievals. For this we need to understand how entries are stored in master datasets.
I like to think of master datasets as magic dartboards with the darts as your data entries. (Actually, I am only thinking of master datasets with ASCII-type keys, since they are the only ones that use hashing. If the key field is of a binary datatype, things happen completely differently.)

You start with an empty dartboard and you throw the first dart.
This is like adding your first entry.
The dart hits the board at a "random" location (this is the "hashing) which becomes it's "primary" location, the place where it "belongs". The magic part of the dartboard is that if you throw the same dart again, it always goes to the same spot. This allows you to find it quickly. In TurboIMAGE terms, you perform repeatable mathematical calculations on the unique key value to produce a "hash location" in the master dataset. This is where that dart always lands.
Does the next dart land right next to the first one? Not likely.
The next dart lands at a new random location and the next and the next. If the hashing is working properly, the darts are spread randomly across the board. As the number of darts increases, the board gets filled and it becomes more likely that one of the darts will hit an existing dart!
When a dart wants to be in the same primary, this is called a collision and leads to placing the dart in a nearby "secondary" location. It takes more work to create, find and maintain secondary entries than it does primary. As the number of entries approaches the capacity of the master dataset, the percentage that are secondaries will increase (assuming that the distribution is actually random, which is sometimes isn't, but that is another story).
Note: TurboIMAGE tries to put colliding entries nearby to their primary location. For this reason, performance only degrades seriously when all the locations in that page of disk space are full and TurboIMAGE has to start reading and examining neighboring pages.
What happens when you increase the capacity of the master dataset?
You must remove all the darts and throw them again, because now each will have a new magic location. In TurboIMAGE terms, you need to start with a new empty master dataset and re-put all the entries. Because there is more space and the hash locations are random, the entries will spread out more, with fewer collisions!
This explains why increasing the capacity usually improves the performance of DBPUT, DBDELETE, DBFIND and DBGET mode 7 (keyed).
Now back to our original question: if increasing the capacity by 50% reduces collisions and improves performance, wouldn't increasing the capacity by 500% improve it even more?
The answer is "Yes and No"!
Yes, most functions will improve by a very small amount. However, once you have reduced the number of secondaries so that 99% of them reside in the same disk page as their primary, you can't improve performance anymore. The minimum time it takes to find an entry is one disk read - once you reach that point, adding unused capacity is pointless.
But there is a more important "No" answer.
If you increase the capacity of a master dataset to create a lot of empty space, at least one function, the serial scan, will be much slower.
A serial scan is a series of DBGET mode 2 calls to look at every entry in a dataset. It is used when you need to select entries by some criteria that is not the key field. For example, you want to select all the customers in the 215 area code, but the key field is customer-id.
Each DBGET mode 2 call must find and return the "next" physical entry in the master dataset. If the dataset is mostly empty, the next physical entry could be far away. But the DBGET cannot complete until it has read all the intervening disk space!
To read all the entries in the master dataset, DBGET must read every page in the dataset until it reaches the last entry. If you increase the size of a master dataset from 10,000 pages to a 100,000 pages, you have made serial scans take 10 times as long!
So increasing the capacity of a master dataset drastically above the expected number of entries is usually a very bad idea.
Note: TurboIMAGE has a new feature called Dynamic Dataset Expansion (MDX), which allows collisions to be put in an overflow area rather than in an adjacent free secondary location. This can be helpful in cases where the entry values are not hashing randomly or you need a quick fix but don't have time to shut the database down to do a capacity change.
For more information on how the internal mechanisms of TurboIMAGE impact performance, read this Robelle tutorial "IMAGE Internals and Performance".
Is a "Zero Secondaries" Report Good News?
By Bob Green, RobelleAs a TurboIMAGE user, you probably know that master datasets have primary entries and secondary entries. Primaries are "good" because they can be located in a single disk read. Secondaries are "bad" because you must search down a chain of indeterminate length from the primary to find them. You would run a Howmessy or Dbgeneral report to find out what percentage secondaries you have in each master dataset.
If secondary entries slow down a master dataset, would a "zero secondaries" be ideal?
No! Just the opposite.
If your master dataset has no secondaries, it means that the key values are not hashing randomly. Instead, they are hashing into some regular pattern (usually into adjacent locations). Here is what a proper "random" dataset looks like, with P for primary and S for secondary:
--------------------------------------------------- | P PP PS P P PSS P P P P | |PP P P P PS P P PS PSS PPP | | P PS PPP P P P P PP PP PSS P| ---------------------------------------------------And here is what a dataset with no secondaries usually looks like:
--------------------------------------------------- | PPPPPPPPPPPP | | PPPPPPPPPPPPP | | PPPPPPPPPPPP | ---------------------------------------------------In this second example, all the entries are primaries and they are all clustered in one area, with no empty space between them. How could this happen?
The reason for this pattern is usually binary keys and transaction numbers.
For example, consider typical invoice numbers that start at 030001 and increase by one: 030002, 030003, 030004, etc. If these invoice numbers are stored in a "Binary" field (J2, I2, P8, etc.) instead of an "Ascii" field (X, Z), IMAGE disables random hashing and calculates the primary location as follows instead:
Divide the rightmost 32 bits of the binary value by the dataset capacity, and use the remainder as the primary location (dividing by the capacity ensures that you produce an entry number between 0 and the capacity).
If you try a few examples, you will see that monotonically increasing key values produce adjacent entry numbers. Assume that the capacity is 1000:
030001 => 1 030002 => 2 030003 => 3What is so bad about that? It seems perfect. Each DBFIND or keyed DBGET will take a maximum of one disk read to find each key value!! Very fast.
Unfortunately, the bad part happens when you change the sequence of invoice numbers to 040001, 040002, 040003,...
040001 => 1 040002 => 2 040003 => 3It is quite possible that the new invoice numbers will hash to the same location as the last batch. This causes a collision. The primary location is already occupied, and DBPUT must find a free space for a secondary entry. But the next physical entry is also occupied. In fact, there may be no free entries for quite a while.
The result of this wraparound collision is that DBPUT may have to search thousands of disk pages. And the next DBPUT, will look at the original location + 1, then do the long search completely over again! If this happens to you, it can freeze your database and your entire application.
What can you do?
- Enable Master Dataset Expansion (MDX) on this dataset. I have never actually done this, but it should help quite a bit, because after searching a short time for an empty space, DBPUT will then go to the overflow area instead. However, this solution is not permanent. The overflow entries are on a single chain that will get longer and longer as you add entries, slowing down inquiries. Before that happens, you should implement one of the other solutions below.
- Increase the capacity of the master dataset and hope that the clusters do not overlap with the new capacity.
- Change the key field from a binary type to an ASCII type, such as X or Z. This of course means changing all the COBOL copylibs and recompiling all the programs, which may be quite time-consuming.
- Convert the application to Eloquence on HP-UX. Since it does not have hashing, Eloquence does not have these problems.
An Addendum: Rene Woc writes:
Bob Green's article on "zero secondaries" explains very well the pitfalls and solutions when using "integer keys" in IMAGE master datasets. However, I believe Bob's article missed a 5th solution, one that guarantees no-secondaries with integer keys, if you know how the key values are assigned. This is the most common case. The solution is described in Fred White's article "Integer Keys: The Final Chapter" available from the Adager's web site. It's the solution Adager customers with "integer keys" use. Any HP3000 user can always call Adager to obtain the proper capacity values for their particular case.
Adager: Do migrating secondaries give you migraines?
If you are going to keep your TurboIMAGE database running at maximum efficiency, you need to know about hashing and migrating secondaries. Here is a classic paper by Alfredo Rego.
Visual Basic and HP 3000 Examples
Remote Procedure Calls allow you to run subroutines across a a network. This example from Transformix shows how to issue TurboIMAGE calls from a Visual Basic program across an network.
TurboIMAGE information from Robelle:
- IMAGE Programming
- IMAGE Internals
- Remote DBA
- Database Hung: Dataset too empty?
- IMAGE Internals and Performance
More TurobIMAGE information from other sources: